前言
Java1.8集合框架索引总结 这里有人整合了一段,可以阅读一下
此外,有人总结的面试题Java集合框架面试总结
这个博主讲的非常精髓,有空也要读一下Java集合框架综述🖊
综述
Collection集合:Set,List,Queue
Map图:(与Collection不同族)HashMap,HashTable,TreeMap,ConcurrentHashMap
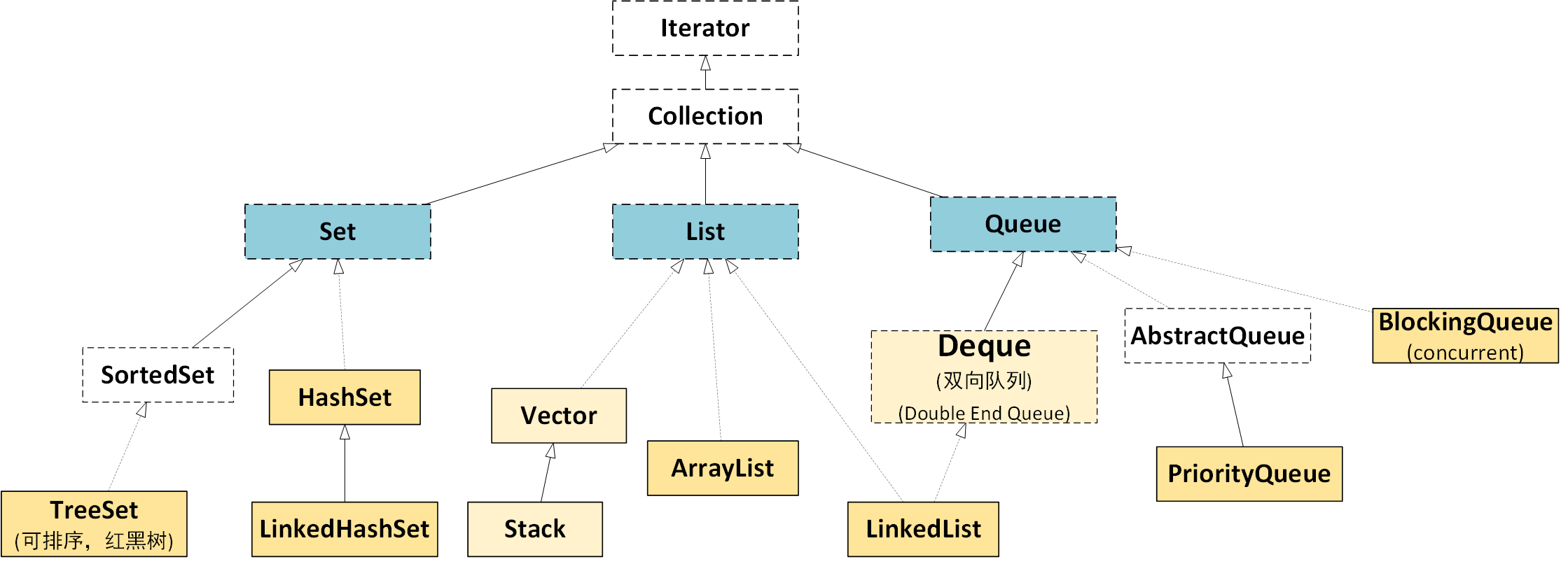
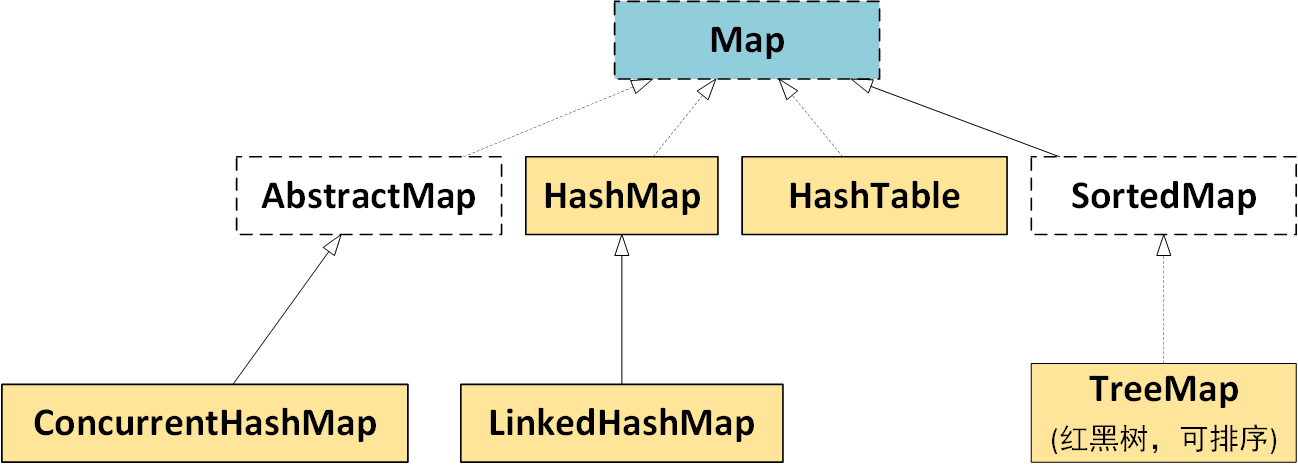
Collection集合
List
ArrayList
特点:查询快,增删慢
实现:动态数组,支持随机访问
默认大小10,默认扩展50%+1个
LinkedList
基于双向链表实现,只能顺序访问,但是可以快速地在链表中间插入和删除元素。
特点:增删块,查询慢
实现:双向链表
实现了Deque双向队列(offer入队,pool出队,peek查看)
可用作Stack栈(push入栈,pop出栈,peek查看)
Vector
与ArrayList相似,数组
线程安全(synchronized),效率低,不推荐
Stack
LIFO先进后出,继承了Vector
数组
线程安全,效率低,不推荐
Set
HashSet
无序,按照Hash算法存储元素,
实现:基于HashMap存储元素(先检查hashCode再检查equals)
特点:存储性能和查询性能良好,不支持有序操作(用Iterator遍历的结果是不确定的)
非线程安全
TreeSet
可排序的Set结构
实现:红黑树,基于TreeMap实现(底层维护一个TreeMap)
支持自然排序和定制排序
但是查找效率不如 HashSet:HashSet 查找时间复杂度为 O(1),TreeSet 则为 O(logN)
LinkedHashSet
HashSet的子类
实现:双向链表 维护元素顺序
特点:具有 HashSet 的查找效率,有插入顺序
总结
HashSet性能最高
实现排序Set:用TreeSet
实现插入顺序:用LinkedHashSet
Set中尽量只添加不可变对象
上述三个Set都是线程不安全的,若需要并发访问,需要手动实现同步。(例Collection.synchronizedSet方法)
Queue
LinkedList
实现双向队列(offer入队,pool出队,peek查看)
PriorityQueue
优先队列
实现:堆结构
Map
HashMap
Entry数组保存key-value
存储和查询时先根据HashCode决定在数组的位置,再根据equals决定其在该数组位置上的链表中的存储位置;
用链地址法解决Hash冲突(解决hash冲突的办法有1. 开放地址法 2. 再哈希法 3. 链地址法 4. 建立公共溢出区)
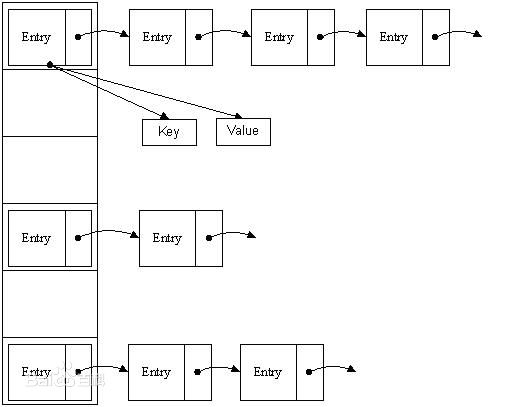
数组默认大小16,加载因子为0.75,可以使用Collections.synchronizeMap(hashMap)实现同步
Java8开始,一个桶存储的链表长度>8时,链表将转为红黑树
关于HashMap的大小设置的问题
HashMap的默认数组大小为16,有两个关键的参数:初始容量和加载因子,加载因子为0.75
初始容量:哈希表在创建时的容量
加载因子:哈希表在其容量自增之前可达到的上限容量
当哈希表中的条目超过了容量 * 加载因子时,对hashMap进行 rehash 操作,将hashMap扩大到两倍桶数。
例题:假如HashMap确认只装100个元素,那么 new HashMap(?) 指定多少是最佳的? 答案:256
原因:如果使用128的话,128<100/0.75=134,可能会引发rehash(),消耗相当大,所以应该向上取256。
首先根据加载因子的计算,100/0.75 = 134,但由于134>128,可能会发生哈希碰撞。
避免哈希碰撞的同时另Hash桶的有效利用:只要将hash表的长度设为2的N次方,那么,所有的哈希桶均有被使用的可能。
(如011&1-1 = 001;001&101=001)他们的值相等了,那么这个时候就会发生哈希碰撞。
除此之外还有一个更加严重的问题,由于在101中第二位是0,那么,无论我们的key在哈希运算之后得到的值h是什么,那么在&运算之后,得到的结果的倒数第二位均为0;
因此,对于hash表所有下标的二进制的值而言,只要低位第二位的值为1,(例如0010,0011,0111,1111)那么这个下标所代表的桶将一直是空的,因为代码中的&运算的结果永远不会产生低位第二位为1的值。这就大大地浪费了空间,同时还增加了哈希碰撞的概率。这无疑会降低HashMap的效率。
那么如何才能减少这种浪费呢?最佳的方法当然是让length-1的二进制值全部位均为1.那么length的值是多少合适呢?没错,length=2^n。
只要将hash表的长度设为2的N次方,那么,所有的哈希桶均有被使用的可能。
由于空间加大和有效利用哈希桶,这时的哈希碰撞将大大降低,因此HashMap的读取效率会比较高。
结果的补充:其实在Java中,无论你的HashMap(x)中的x设置为多少,HashMap的大小都是2^n。2^n是大于x的第一个数。因为HashMap的初始化代码中有以下这行代码:
1 | int capacity = 1; |
但是这就带来了一个问题,如果x=100,那么HashMap的初始大小应该是128。但是100/128=0.78,已经超过默认加载因子的大小了。因此会resize一次,变成256。所以最好的结果还是256。
关于hashMap的总结这里还有更多:HashMap总结:链接
LinkedHashMap
实现:双向链表 维护元素的顺序,
顺序:插入顺序 或 最近最少使用(LRU)顺序。
TreeMap
实现:红黑树
TreeMap集合默认会对键进行排序,所以键必须实现自然排序和定制排序中的一种
HashTable
数据结构 HashMap 一致,但它是线程安全的,但Hashtable则会锁定整个map
它是遗留类,不应该去使用它。
现在可以使用 ConcurrentHashMap 来支持线程安全,并且 ConcurrentHashMap 的效率会更高,因为 ConcurrentHashMap 引入了分段锁。
ConcurrentHashMap
线程安全:分段锁机制:ConcurrentHashMap仅仅锁定map的某个部分
高效的线程安全
Map类集合K/V能不能存储null值的情况
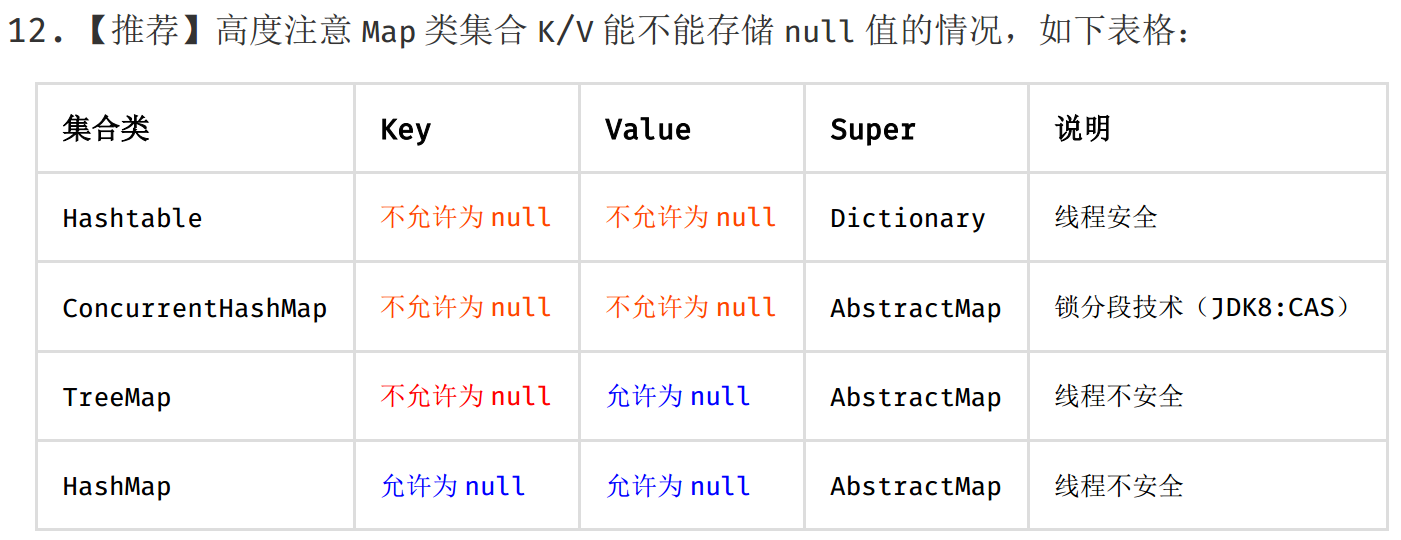
只有HashMap可以都为null,以及Tree只允许Value为null(key要排序),其他都不能为null